
自主移动机器人的基本要求之一是其导航能力。机器人必须能够按照给定的坐标从当前位置导航到地图上指定的目标位置,同时还要避开周围的障碍物。在某些情况下,需要机器人能够以较高的导航速度尽快到达目的地。然而,导航速度较快的机器人通常具有较高的碰撞风险,额能会影响到机器人和周围环境。
为了解决这个问题,丰桥工业大学(TUT)计算机科学与工程系主动智能系统实验室(AISL)的研究小组提出了一个新的框架,用于训练移动机器人快速导航,同时保持低碰撞率。该框架在训练过程中结合了深度强化学习(DRL)和课程学习,让机器人学会快速又安全的导航策略。
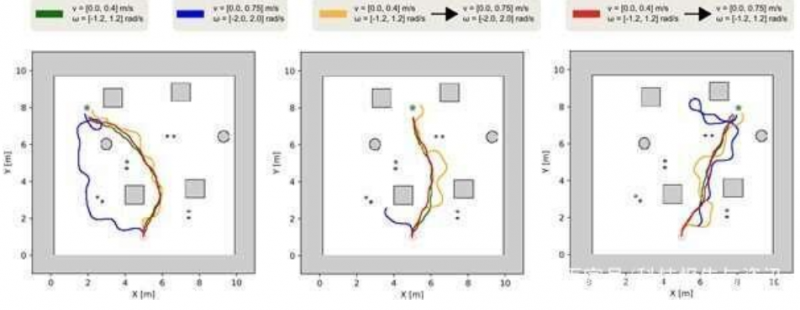
论文第一作者、博士生Chandra Kusuma Dewa解释说,DRL可以使机器人通过反复尝试各种动作,根据环境的当前状态(如机器人位置和障碍物放置)学习适当的动作。此外,当前动作的执行会在机器人达到目标位置或与障碍物发生碰撞时立即停止,因为学习算法假设动作已经被机器人成功执行,该后果需要用于改进策略。所提出的框架可以帮助维持学习环境的一致性,使机器人可以学习到更好的导航策略。
此外,TUT的AISL负责人Jun Miura教授介绍说:“该框架遵循课程学习策略,在训练情节开始时为机器人设定一个小的速度值。随着集数的增加,机器人的速度会逐渐增加,这样机器人就可以在训练环境中从最简单的关卡(如动作缓慢的关卡)到最困难的关卡(如动作快速的关卡),逐渐学会快速又安全的导航这一复杂任务。
由于训练阶段的碰撞是不可取的,所以学习算法的研究通常是在模拟环境中进行的。研究人员模拟了室内环境进行实验。实践证明,所提出的框架在训练和验证过程中,与之前已有的其他框架相比,都能使机器人的导航速度更快,成功率最高。研究人员认为,根据评估结果,该框架是有价值的,它可以广泛应用于任何需要快速但安全导航的领域的移动机器人的训练。
论文标题为《A framework for DRL Navigation With State Transition Checking and Velocity Increment Scheduling》,发表在《IEEE Access》上。
 博威合金BOWAY
博威合金BOWAY 马扎克Mazak
马扎克Mazak 威尔泰克
威尔泰克 迈格泰克
迈格泰克 斯巴特
斯巴特 MAOSHENG贸盛
MAOSHENG贸盛 Miller米勒
Miller米勒 新世纪焊接
新世纪焊接 西安恒立
西安恒立 上海特焊
上海特焊 新天激光
新天激光 海目星激光
海目星激光 迅镭激光
迅镭激光 粤铭YUEMING
粤铭YUEMING 镭鸣Leiming
镭鸣Leiming 领创激光
领创激光 天琪激光
天琪激光 亚威Yawei
亚威Yawei 邦德激光bodor
邦德激光bodor 扬力YANGLI
扬力YANGLI 宏山激光
宏山激光 楚天激光
楚天激光 百超迪能NED
百超迪能NED 金运激光
金运激光 LVD
LVD Tanaka田中
Tanaka田中 BLM
BLM 易特流etal
易特流etal 百盛激光
百盛激光 Messer梅塞尔
Messer梅塞尔 PrimaPower普玛宝
PrimaPower普玛宝 Salvagnini萨瓦尼尼
Salvagnini萨瓦尼尼 奔腾激光PENTA LASER
奔腾激光PENTA LASER 华工HGTECH
华工HGTECH Bystronic百超激光
Bystronic百超激光 TRUMPF通快
TRUMPF通快 川崎工业焊接机器人 焊接管架
川崎工业焊接机器人 焊接管架 上海通用电气 全焊机系列展示
上海通用电气 全焊机系列展示 大焊 焊机匠心品质 精工之作 行家之选
大焊 焊机匠心品质 精工之作 行家之选 KUKA 库卡摩多机器人流水线作业
KUKA 库卡摩多机器人流水线作业 创力 CANLEE光纤激光切割机
创力 CANLEE光纤激光切割机 松下 旗下LAPRISS机器人激光焊接系统
松下 旗下LAPRISS机器人激光焊接系统 全自动焊接流水线
全自动焊接流水线 科弧PM-220无气自保焊机 不用气的气保焊机 PM220无气自保焊机 便携式220V二保焊机 电焊机
科弧PM-220无气自保焊机 不用气的气保焊机 PM220无气自保焊机 便携式220V二保焊机 电焊机 焊接变位机
焊接变位机 弧焊机器人,焊接机器人 川崎焊接机器人
弧焊机器人,焊接机器人 川崎焊接机器人 TO300A300A柴油发电焊机,发电带电焊机
TO300A300A柴油发电焊机,发电带电焊机 小型自动氩弧焊机厂家供应
小型自动氩弧焊机厂家供应 co2二氧化碳保焊机汽车气保焊机小型220v价格
co2二氧化碳保焊机汽车气保焊机小型220v价格 自主可控国产碳化硅SiC MOSFET单管及模块
自主可控国产碳化硅SiC MOSFET单管及模块 销售一批 焊接滚轮架 可定做 滚轮架
销售一批 焊接滚轮架 可定做 滚轮架








